Start of topic | Skip to actions
Provenance Challenge: Southampton
Participating Team
Team and Project Details
- Short team name: Southampton
- Participant names: Simon Miles, Paul Groth, Steve Munroe, Sheng Jiang, Luc Moreau, Thibaut Assandri
- Project URL: http://www.pasoa.org, http://www.gridprovenance.org
- Project Overview:
- PASOA (Provenance Aware Service Oriented Architecture) aims to investigate the concept of provenance and its use for reasoning about the quality and accuracy of data in the context of e-Science.
- The overarching aim of EU Provenance is to design, conceive and implement an industrial strength open provenance architecture for grid systems, and to deploy and evaluate it in complex grid applications, namely aerospace engineering and organ transplant management.
Provenance-specific Overview
Following our extensive requirements capture in multiple application domains (including bioinformatics, high energy physics, medicine and chemistry) [Miles JOGC06], we have defined an open architecture for provenance [Groth 06]. This architecture is designed to be domain independent and technology independent (whether web services, grid middleware or standalone applications). Since electronic data does not typically contain the necessary historical information that would help end-users to understand its origin, there is a need to capture extra information, which we name process documentation, describing what actually occurred at execution time. Provenance-aware applications create process documentation and store it in a provenance store, the role of which is to offer long-term, persistent, secure storage of process documentation Our motivation was to define an open architecture, hence we have specified open data models and interfaces. The models and interfaces, which have just been released publicly, can be found below. We have also implemented elements of this architecture. In particular, PReSerV [Groth AHM05] is a provenance store, which can be used to record process documentation into, and which offers a provenance query facility [Miles IPAW06] for scoping the provenance of data. The Provenance CSL (Client Side Library) facilitates the embedding of the provenance architecture in Java applications. We have used our software in a number of applications, including a Bioinformatics Experiment [Groth HPDC05, Wong ISWC06]. Architecture components are also implemented by IBM Hursley (Provenance Store) and Cardiff (see entry in this twiki), and are deployed in a medical application (Organ Transplant Management) and aerospace engineering application. Finally, to accompany the architecture, we have defined a methodology that helps designers to transform applications into provenance aware applications [Munroe 06]. A complete tutorial was produced by the Southampton team and is available from here.Relevant Publications
- Vikas Deora, Arnaud Contes, Omer F. Rana, Shrija Rajbhandari, Ian Wootten, Kifor Tamas, and Laszlo Z.Varga. Navigating Provenance Information for Distributed Healthcare Management. In IEEE/WIC/ACM Web Intelligence Conference, 2006.
- Paul Groth, Sheng Jiang, Simon Miles, Steve Munroe, Victor Tan, Sofia Tsasakou, and Luc Moreau. An Architecture for Provenance Systems --- Executive Summary. Technical report, University of Southampton, February 2006. [WWW ]
- Paul Groth, Sheng Jiang, Simon Miles, Steve Munroe, Victor Tan, Sofia Tsasakou, and Luc Moreau. D3.1.1: An Architecture for Provenance Systems. Technical report, University of Southampton, February 2006. [WWW ]
- Tamás Kifor, László Varga, Sergio Álvarez, Javier Vázquez-Salceda, and Steven Willmott. Privacy Issues of Provenance in Electronic Healthcare Record Systems. In First International Workshop on Privacy and Security in Agent-based Collaborative Environments (PSACE2006), AAMAS 2006, 2006. [WWW ]
- Tamás Kifor, László Varga, Sergio Álvarez, Javier Vázquez-Salceda, Steven Willmott, Simon Miles, and Luc Moreau. Provenance in Agent-Mediated Healthcare Systems. In IEEE Intelligent Systems Special Issue on Intelligent Agents in Healthcare, 2006. IEEE.
- Guy K. Kloss and Andreas Schreiber. Provenance Implementation in a Scientific Simulation Environment. In Proceedings of the International Provenance and Annotation Workshop (IPAW), Chicago, Illinois, USA, May 2006. [WWW ]
- Luc Moreau. Usage of `provenance: A Tower of Babel. Towards a concept map --- Position paper for the Microsoft Life Cycle Seminar, Mountain View, July 10, 2006. Technical report, University of Southampton, June 2006. [WWW ]
- Luc Moreau and John Ibbotson. Standardisation of Provenance Systems in Service Oriented Architectures --- White Paper. Technical report, University of Southampton, 2006. [WWW ]
- Steve Munroe, Simon Miles, Victor Tan, Paul Groth, Sheng Jiang, Luc Moreau, and John Ibbotson, and Javier Vázquez-Salceda. PrIMe: A Methodology for Developing Provenance-Aware Applications. Technical report, University of Southampton, 2006. [WWW ]
- Shrija Rajbhandari, Arnaud Contes, Omer F.Rana, Vikas Deora, and Ian Wootten. Trust Assessment Using Provenance in Service Oriented Application. In First Int. Workshop on Service Intelligence and Service Science (SISS 2006), co-located with EDOC 2006 conference, 2006.
- Shrija Rajbhandari, Ian Wootten, Ali Shaikh Ali, and Omer F. Rana. Evaluating Provenance-based Trust for Scientific Workflows. In CCGrid06, 2006. IEEE Computer Society Press.
- Ian Wootten, Shrija Rajbhandari, Omer Rana, and Jaspreet Pahwa. Actor Provenance Capture with Ganglia. In CCGrid06, 2006. IEEE Computer Society Press. [WWW ]
- Ian Wootten, Omer Rana, and Shrija Rajbhandari. Recording actor state in scientific workflows. In Proceedings of the International Provenance and Annotation Workshop (IPAW), 2006. [WWW ]
- Sergio Álvarez, Javier Vázquez-Salceda, Tamás Kifor, László Varga, and Steven Willmott. Applying Provenance in Distributed Organ Transplant Management. In International Provenance and Annotation Workshop (IPAW'06), 2006. [WWW ]
- Paul Groth, Victor Tan, Steve Munroe, Sheng Jiang, Simon Miles, and Luc Moreau. Process Documentation Recording Protocol. Technical report, University of Southampton, 2006. [WWW ]
- Simon Miles, Luc Moreau, Paul Groth, Victor Tan, Steve Munroe, and Sheng Jiang. Provenance Query Protocol. Technical report, University of Southampton, 2006. [WWW ]
- Simon Miles, Luc Moreau, Paul Groth, Victor Tan, Steve Munroe, and Sheng Jiang. XPath Profile for the Provenance Query Protocol. Technical report, University of Southampton, 2006. [WWW ]
- Simon Miles, Steve Munroe, Paul Groth, Sheng Jiang, Victor Tan, John Ibbotson, and Luc Moreau. Process Documentation Query Protocol. Technical report, University of Southampton, 2006. [WWW ]
- Steve Munroe, Paul Groth, Sheng Jiang, Simon Miles, Victor Tan, and Luc Moreau. Data model for Process Documentation. Technical report, University of Southampton, 2006. [WWW ]
- Steve Munroe, Simon Miles, Victor Tan, Paul Groth, Sheng Jiang, Luc Moreau, and John Ibbotson, and Javier Vázquez-Salceda. PrIMe: A Methodology for Developing Provenance-Aware Applications. Technical report, University of Southampton, 2006. [WWW ]
- Steve Munroe, Victor Tan, Paul Groth, Sheng Jiang, Simon Miles, and Luc Moreau. A SOAP Binding For Process Documentation. Technical report, University of Southampton, 2006. [WWW ]
- Steve Munroe, Victor Tan, Paul Groth, Sheng Jiang, Simon Miles, and Luc Moreau. A WS-Addressing Profile for Distributed Process Documentation. Technical report, University of Southampton, 2006. [WWW ]
- Steve Munroe, Victor Tan, Paul Groth, Sheng Jiang, Simon Miles, and Luc Moreau. The Provenance Standardisation Vision. Technical report, University of Southampton, 2006. [WWW ]
- Victor Tan, Paul Groth, Sheng Jiang, Simon Miles, Steve Munroe, and Luc Moreau. WS Provenance Glossary. Technical report, Electronics and Computer Science, University of Southampton, 2006. [WWW ]
- Victor Tan, Steve Munroe, Paul Groth, Sheng Jiang, Simon Miles, and Luc Moreau. A Profile for Non-Repudiable Process Documentation. Technical report, University of Southampton, 2006. [WWW ]
- Victor Tan, Steve Munroe, Paul Groth, Sheng Jiang, Simon Miles, and Luc Moreau. Basic Transformation Profile for Documentation Style. Technical report, University of Southampton, 2006. [WWW ]
Workflow Representation
We simulated the execution of the workflow by a mockup Java program operating directly on the URLs for the different input files, and producing URLs for the various outputs and intermediary results. Our simulator relies on a class for each of the following workflow components:AlignWarp, Reslice, Softmean, Convert, Slicer, Challenge. URLs and parameter strings are exchanged by the different workflow components.
From now onwards, we use the term actor, to mean an active component of a workflow, interchangeably with service.
Note that our approach to provenance recording is independent of the actual technology used to execute the workflow. The same process documentation (or a very similar documentation) could have been produced from other workflow implementations (batch file, VDT, ...) and other technologies such as Web Services or command-line applications.
As the Java program executes, it creates and records p-assertions by using the Provenance CSL (Client Side Library), according to a model that we now describe.
Provenance Trace
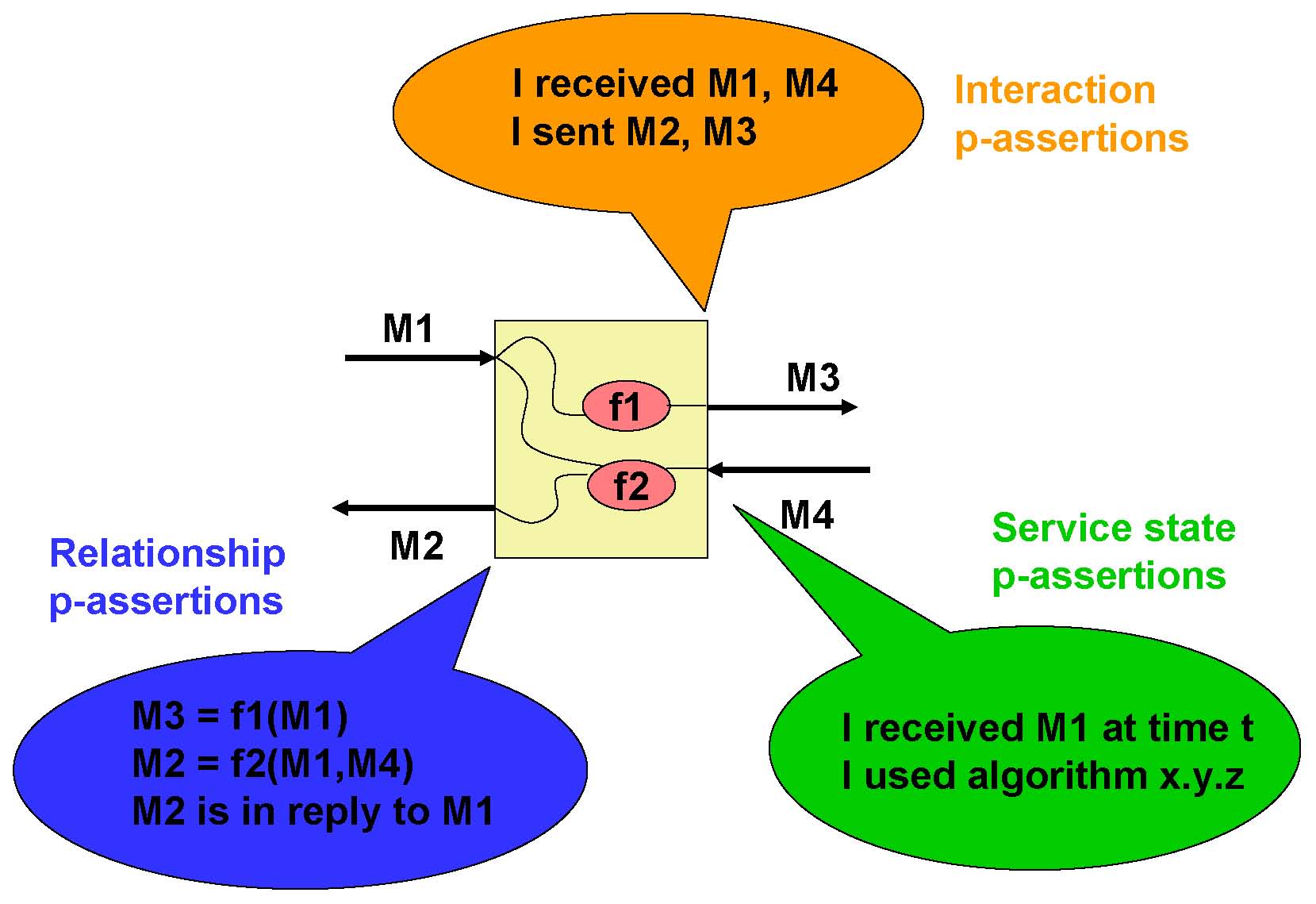
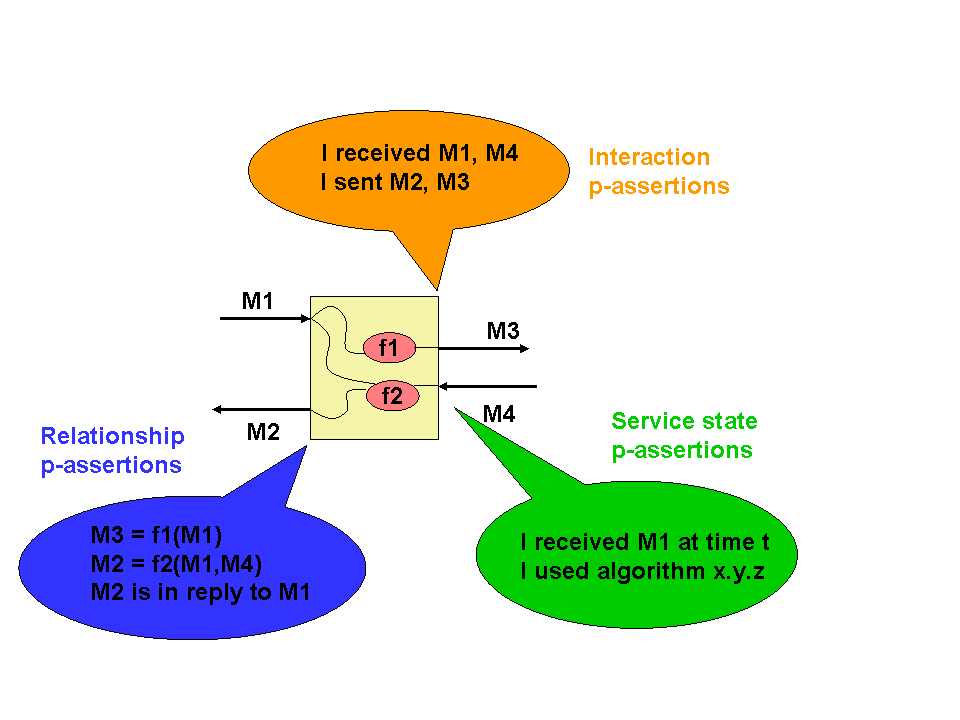
For many applications, process documentation cannot be produced in a single, atomic burst, but instead its generation must be interleaved continuously with execution. Given this, it is necessary to distinguish a specific item documenting part of a process from the whole process documentation. We see the former --- referred to as a p-assertion --- as an assertion made by an individual application service involved in the process. Thus, the documentation of a process consists of a set of p-assertions made by the services involved in the process. In order to minimize its impact on application performance, documentation needs to be structured in such a way that it can be constructed and recorded autonomously by services, on a piecemeal basis. Otherwise, should synchronizations be required between these services to agree on how and where to document execution, application performance may suffer dramatically. To satisfy this design requirement, various kinds of p-assertions have been identified, as illustrated in the figure below.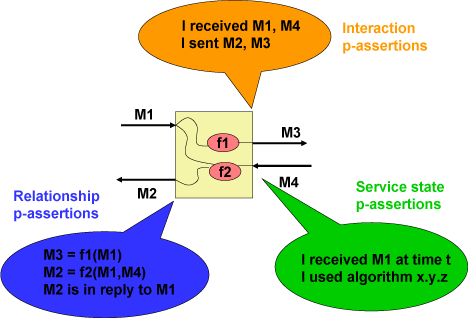
Interactions P-Assertions
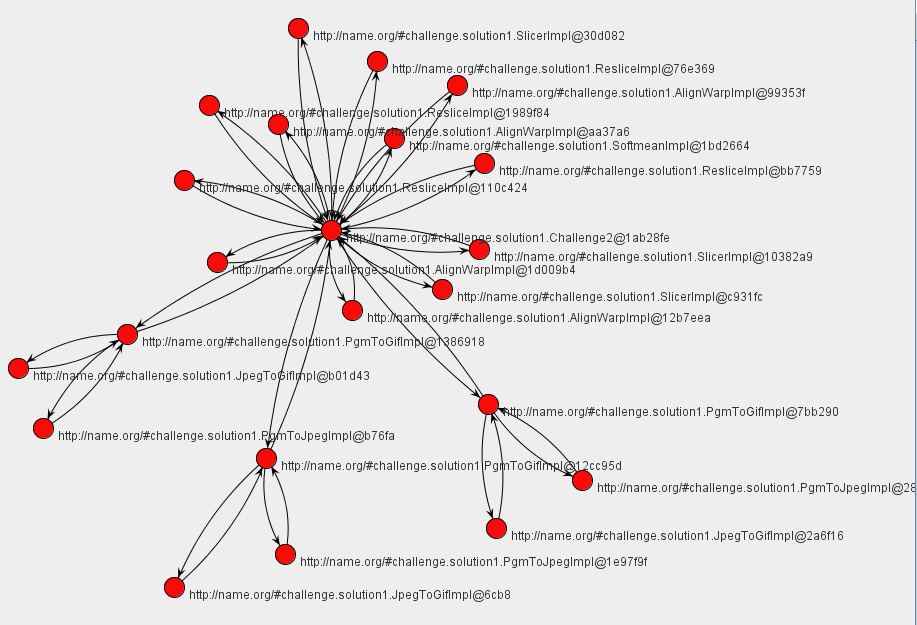
In Service Oriented Architectures, interactions consist of messages exchanged between application services. By capturing all interactions, one can analyze an execution, verify its validity, or compare it with other executions. Therefore, process documentation includes interaction p-assertions, where an interaction p-assertion is a description of the contents of a message by a service that has sent or received that message. With all the interactions between actors, we can define an interaction matrix that specifies which actor is interacting with each other actor, and the number of its interactions (in the figure denoted by a gradiant of red).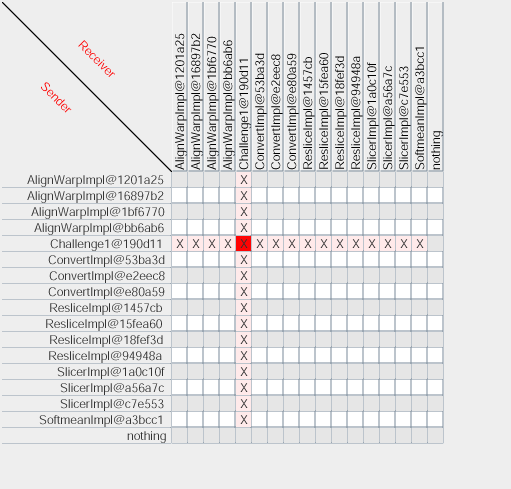 Alternatively, we can define a UML-style collaboration diagram.
Alternatively, we can define a UML-style collaboration diagram.
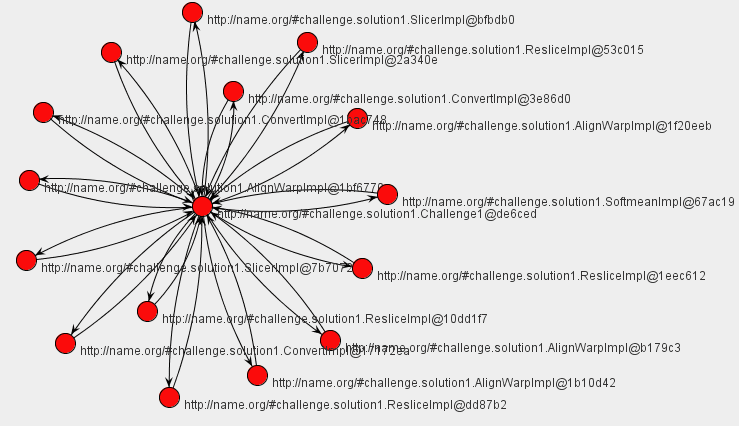 In both cases, for our implementation of the workflow, we see that there is a central component, the enactor, which invokes each of the actors identified in the Challenge workflow.
In both cases, for our implementation of the workflow, we see that there is a central component, the enactor, which invokes each of the actors identified in the Challenge workflow.
Relationships P-Assertions
Generally, whether a service returns a result directly or calls other services, the relationship between its outputs and inputs is not explicitly represented in messages themselves, but can be understood only by an analysis of the service's business logic. To promote openness and generality, we do not make any assumption about the technology used by services to implement their business logic (such as source code, workflow language, etc.). Instead, we place a requirement on services to provide some information, in the form of relationship p-assertions: a relationship p-assertion is a description, asserted by a service, of how it obtained output data sent in an interaction by applying some function, or algorithm, to input data from other interactions. In the figures below, we show an actor view for each of the actors in the workflow. On the left-hand side, we see inputs to the actors, and on the right-hand side we see its outputs. For each output, the actor view identifies how it was computed based on its inputs, all this expressed as relationships.


 The five workflows steps are quite straightforward to understand since each one them produces an output for a set of inputs. On the other hand, the dataflow within the enactor is far more complex, since it takes outputs of actors it invoked, to pass them as inputs to other actors. The same actor view for the Challenge enactor is as follows.
The five workflows steps are quite straightforward to understand since each one them produces an output for a set of inputs. On the other hand, the dataflow within the enactor is far more complex, since it takes outputs of actors it invoked, to pass them as inputs to other actors. The same actor view for the Challenge enactor is as follows.
 Interaction and relationship p-assertions taken together capture an explicit description of the flow of data in a process: interaction p-assertions denote data flows between services, whereas relationship p-assertions denote data flows within services. Such data flows capture the causal and functional data dependencies that occurred in execution and, in the most general case, constitute a directed acyclic graph (DAG).
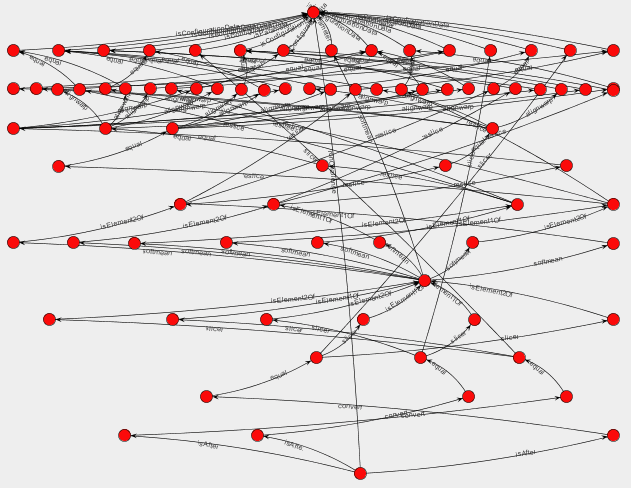
The figure below shows what the complete DAG is for the Provenance Challenge. At the top, we see the message requesting the execution of the Challenge workflow, and at the bottom we see the message indicating the end of its execution; the later is obtained because we obtained three gifs, data products of the
Interaction and relationship p-assertions taken together capture an explicit description of the flow of data in a process: interaction p-assertions denote data flows between services, whereas relationship p-assertions denote data flows within services. Such data flows capture the causal and functional data dependencies that occurred in execution and, in the most general case, constitute a directed acyclic graph (DAG).
The figure below shows what the complete DAG is for the Provenance Challenge. At the top, we see the message requesting the execution of the Challenge workflow, and at the bottom we see the message indicating the end of its execution; the later is obtained because we obtained three gifs, data products of the Convert operation. We see that dealing with such a graph becomes very quickly impractical for users, when experiment size increases. Hence, we need mechanisms by which we can identify parts of the DAG that are relevant to the user.
Actor States P-Assertions
Beyond the flow of data in a process, internal actor states may also be necessary to understand non-functional characteristics of execution, such as performance or accuracy of services, and therefore the nature of the result they compute. Hence, we define an actor state p-assertion as documentation provided by an actor about its internal state in the context of a specific interaction. Actor state p-assertions can be extremely varied: they may include the workflow that is being executed, the amount of disk and CPU time a service used in a computation, its local time when an action occurred, the floating point precision of the results it produced, or application-specific state descriptions. In the provenance challenge, actor states are used to represent three types of information.- The user-friendly name of an actor and its type, collectively called the actor profile. This information is used in answering queries 6, 7 and 8 as described in detail below.
- Annotations on data items recorded in p-assertions, stating a property that was true of the data item at the time that the annotation was asserted. This information is used in answering queries 8 and 9 below.
- Notes of the injection or removal of tracers into/from messages, discussed further below. This information could be used to help answer query 7 below.
Tracers
Tracers are unique identifiers passed through processes by the actors in those processes. By this means, a tracer acts as a demarcation of a process (which may be a sub-process of higher-level processes). They can be used by queriers as a convenient means to extract documentation regarding a whole process. A commonly useful type of tracer is the session tracer. This demarcates the whole process that occurs for an actor to perform an operation. Wherever the actor, in the course of performing the operation, sends a message to another actor it will introduce (inject) a session tracer into that message. The actor to which it is sent will forward it on to other actors in other interactions in the same process, they will forward it on to others etc. When the operation is finished, the actor that originally introduced the tracer then removes it. Removal of a tracer does not mean that the tracer is actually removed from any message, only that it will not be put in any more messages in the future.The P-Structure
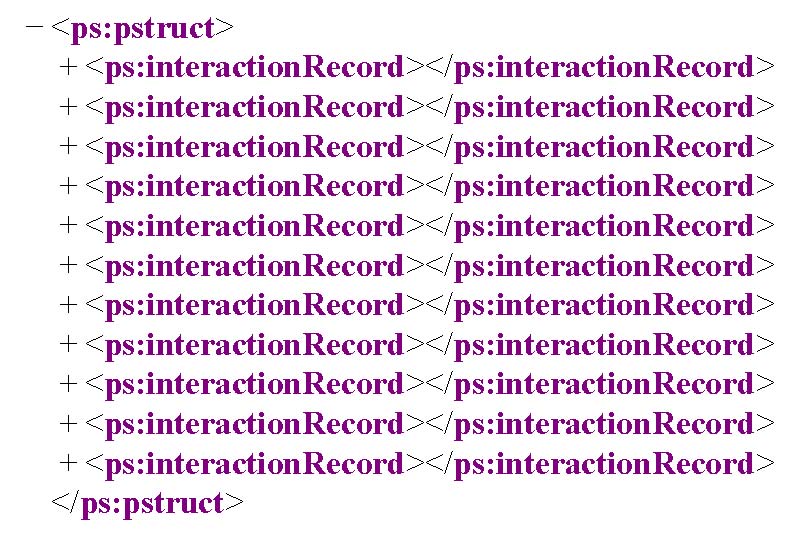
The P-Structure is a conceptual view of the provenance store shared by asserters and queriers. Such a conceptual model is crucial since it allows asserters to make assertions that will be understood, in context, by queriers. The P-Structure is structured according to the interactions, where all information pertaining an interaction is encapsulated in an interaction record. Given that an interaction is defined as the exchange of a message between a sender and a receiver, both
parties have the possibility of documenting their involvement in the message exchange.
Given that an interaction is defined as the exchange of a message between a sender and a receiver, both
parties have the possibility of documenting their involvement in the message exchange.
 Each view is composed of a set of p-assertions, and the identity of the actor who makes these assertions.
Each view is composed of a set of p-assertions, and the identity of the actor who makes these assertions.
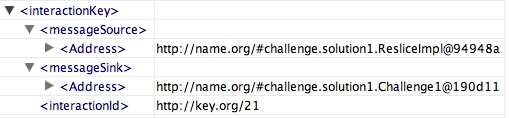
 For actors to be able to document their execution without having to synchronise in order to decide how to organise their documentation in a consistent manner, we need a mechanism by which interactions can be unambiguously identified. For this, we introduce interactions keys, as composed of the sender endpoint, the receiver endpoint, and a message id (expected to be locally unique between this sender and receiver).
For actors to be able to document their execution without having to synchronise in order to decide how to organise their documentation in a consistent manner, we need a mechanism by which interactions can be unambiguously identified. For this, we introduce interactions keys, as composed of the sender endpoint, the receiver endpoint, and a message id (expected to be locally unique between this sender and receiver).
Provenance Queries
In Sections below, we describe how we answered each of the queries, using the architecture described above. A summary of our results is given in the ProvenanceQueriesMatrix, and our row of this matrix is shown below.| Teams | Queries | ||||||||||
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | |||
| Southampton team |  | | | | | | | | | ||
Implementation
The code to perform the challenge queries was written in Java. The full code is given here, with key extracts and queries being listed below. The primary actions performed by the code, are calls to a provenance store Web Service, using two query interfaces:- The provenance query interface iteratively traverses the relationship p-assertions to find all events and data that comprise the provenance of a data item. The specification of this type of query can be found in [Miles IPAW06]).
- The process documentation query interface evaluates XQuery expressions over the p-structure, as defined above.
Depiction of Results
The result data are attached to this page and referenced from the individual sections. For the first three queries, the results of provenance queries are also shown in a graphical form. Due to the detail contained in the provenance query results, the images on the page are not always readable. However, they link to high-quality PDF versions. An example is given below.
Query 1
Find the process that led to Atlas X Graphic / everything that caused Atlas X Graphic to be as it is. This should tell us the new brain images from which the averaged atlas was generated, the warping performed etc. Provenance Queries This is a typical use of our provenance query interface. A provenance query is comprised of two parts:- The query data handle is a specification of the data item of which to find the provenance.
- The relationship target filter is a specification of the scope of the query, i.e. what information is relevant or irrelevant to return.
- In line (4), we specify the URL of the actor that sent the data (the convert service in the workflow)
- In line (5), we specify the URL of the actor that received the data (the challenge workflow enactor)
- In line (6), we specify that we want the provenance from the instant that the image was received
- In line (7), we specify an XPath into the contents of the message containing the data item by which we can find that item, including the name of the file itself
(1) dataItem = "challenge/atlas-x.gif";
(2) builder = new ProvenanceQueryBuilder (_spaces);
(3) builder.getQDHBuilder ().
(4) sourceURL (convertURL).
(5) sinkURL (enactorURL).
(6) receiver ().
(7) contentItem ("/java/object/void/object[string='" + dataItem + "']");
(8) results = client.provenanceQuery (builder.build ());
When sent to a provenance store, the provenance query translates into two XPaths: one for the query data handle, one for the relationship target filter. Below we show the XPath for the query data handle. Within the provenance store, it is evaluated over the p-structure to find the data item of which to find the provenance. The lines have been annotated with (3), (4), (5) and (6) to show how the calls to the Java builder above translate to parts of an XPath below. In presenting this, and subsequent queries we split them into lines for readability, but they should be read as a single XPath.
/ps:pstruct/ps:interactionRecord
(4) [ps:interactionKey/ps:messageSource/wsa:Address='http://name.org/#challenge.solution1.ConvertImpl@3e86d0']
(5) [ps:interactionKey/ps:messageSink/wsa:Address='http://name.org/#challenge.solution1.Challenge1@de6ced']
(6) /ps:receiver
(7) /ps:interactionPAssertion/ps:content/java/object/void/object[string='challenge/atlas-x.gif']
Relationship Target Filters
The relationship target filter, which specifies scope, is given to a provenance store as an XPath over a a relationship target. This is an XML document containing the full set of information about a data item which is considered for inclusion in the provenance query results. If the XPath discovers (evaluates to) one or more nodes, then the data item is in scope, if zero then it is not in scope.
In this query, the results are unscoped, i.e. we do not specify any limitations on the search for data in the process that led to the Atlas X Graphic.
The relationship target filter XPath for this query is shown below: this will match any piece of data that is related by relationship p-assertions to the Atlas X Graphic.
(1) /pq:relationshipTargetThe results of the query can be found here. They are graphically depicted below.
Query 2
Find the process that led to Atlas X Graphic, excluding everything prior to the averaging of images with softmean. The second query is also a straightforward provenance query. However, in this case the query is scoped to only include certain information. Therefore a relationship target filter must be specified. This is achieved by stating what properties data must have in order to be included or excluded from the query results. Scoping on Relationship Type The code below is the same as for Query 1, except that the relationship target filter is specified. In line (9), we specify that the provenance query should not include relations of type "http://relation.org/softmean". This is the term used by the softmean actor to relate its inputs to its outputs, meaning that the provenance query results will include the outputs of the softmean actor but not the inputs or anything prior to the inputs.
(1) dataItem = "challenge/atlas-x.gif";
(2) builder = new ProvenanceQueryBuilder (_spaces);
(3) builder.getQDHBuilder ().
(4) sourceURL (source).
(5) sinkURL (sink).
(6) receiver ().
(7) contentItem ("/java/object/void/object[string='" + dataItem + "']");
(8) builder.getRTFBuilder ().
(9) .notRelation ("http://relation.org/softmean");
(10) results = client.provenanceQuery (builder.build ());
The query data handle is the same as for Query 1. The relationship target filter for this query translates to the XPath given below.
/pq:relationshipTarget
(9) [fn:not(ps:relation='http://relation.org/softmean')]
The results of the query can be found here. They are graphically depicted below.
Query 3
Find the Stage 3, 4 and 5 details of the process that led to Atlas X Graphic. This is another provenance query, scoped at a different stage to the last, i.e. data prior to reslice is excluded.(1) /pq:relationshipTarget (2) [fn:not(ps:relation='http://relation.org/reslice')]The results of the query can be found here. They are graphically depicted below.
Query 4
Find all invocations of procedure align_warp using a twelfth order nonlinear 1365 parameter model (see model menu describing possible values of parameter "-m 12" of align_warp) that ran on a Monday. Process Documentation Queries This query is best expressed as a process documentation query, i.e. an XQuery over whole contents of a provenance store following the p-structure schema. There are three parts to the query below. In line (1), we specify that we want the sender's view, i.e. the workflow enactor's view of its invocation of align_warp. In line (2), we specify that it should run on Monday, coded here as a date string. In line (3), we specify the arguments that the align_warp service must have had. Finally, in line (4), we specify that we want returned the interaction key which identifies this invocation and can be used to retrieve details about it.(1) $ps:pstruct/ps:interactionRecord/ps:sender (2) [ps:interactionPAssertion/ps:content/java/object/void/object/void/object/long='1157626153750'] (3) [ps:interactionPAssertion/ps:content/java/object/void/array/void/string='-m 12 -q'] (4) /../ps:interactionKeyThe results of the query are found here. From an interaction key, we can issue a simple XQuery to get p-assertions about the identified interaction, as shown in other queries below.
Query 5
Find all Atlas Graphic images outputted from workflows where at least one of the input Anatomy Headers had an entry global maximum=4095. The contents of a header file can be extracted as text using the scanheader AIR utility. Documentation Style This query requires multiple steps using both query interfaces. Further it requires use of a feature of the p-structure called documentation style. When a p-assertion is created, the actor that creates it can encode the p-assertion's content in some form. For example, they may encrypt the data, replace the actual data with a reference to the data in a database, anonymise sensitive identifiers etc. Then, to let queriers know that this transformation has taken place, the asserter records a documentation style identifier, by which the querier can understand what has occurred. In our running of the workflow we have transformed the binary image header files into XML representations. This is a two step process: first AIR's scan_header utility is used to convert from binary to a properties file (key=value pairs). Then these properties are transformed into an XML depiction of the same. The documentation style of the interaction p-assertions including the image header files is set to a particular value, shown on line (2) below, to indicate that this occurs. A querier can then search for headers encoded in that format so that it knows how to process them further, e.g. to check values of individual properties. The XQuery below queries for interactions (1) in which an image header is encoded in the XML style (2) and the "global maximum" property is set to 4095 in that file (3), returning the interaction key which identifies the interaction where this took place. The check on the XML header file is performed by a application-specific XQuery function, air:globalMaximum.(1) $ps:pstruct/*/*/ps:interactionPAssertion (2) [ps:documentationStyle='http://www.pasoa.org/schemas/ontologies/DocumentationStyle.Java_Header_XMLEncoding'] (3) [air:globalMaximum(ps:content/java/object/void/array/void[1]/object/string/text())='4095'] (4) /../../ps:interactionKeyOnce we have found the exchanged image headers with the correct criteria, we then need to find out which processes included those interactions. We first do a provenance query for each Atlas Graphic image. This follows exactly the same format as in Query 1. The result is the documentation of the process that led to each image. The query data handle and relationship target are given below (see Query 1 for an explanation).
/ps:pstruct/ps:interactionRecord [ps:interactionKey/ps:messageSource/wsa:Address='http://name.org/#challenge.solution1.ConvertImpl@3e86d0'] [ps:interactionKey/ps:messageSink/wsa:Address='http://name.org/#challenge.solution1.Challenge@de6ced'] /ps:receiver/ps:interactionPAssertion/ps:content/java/object/void/object[string='challenge/atlas-x.gif']
/pq:relationshipTargetFinally, we look through the provenance query results produced by the second step to find the interaction keys found in the first step. This is done in Java, by traversing the data as shown below. Wherever the provenance query results contain the interaction key of an image header with global maximum = 4095, we have determined that the Atlas Graphic of which those results are the provenance fulfils the criteria of Query 5.
output.write ("Interactions producing images resulting from global maximum = 4095 headers:\n");
while (eachProc.hasNext ()) {
if (ProvenanceQueryUtilities.extractInteractionKeys ((ProvenanceQueryResults) eachProc.next ()).
contains (ikey)) {
output.write (ikey.toString ());
}
}
The results of the query are:
Interactions producing images resulting from global maximum = 4095 headers:
source:
<Address xmlns = "http://schemas.xmlsoap.org/ws/2004/03/addressing">
http://name.org/#challenge.solution1.Challenge1@de6ced
</Address>
sink:
<Address xmlns = "http://schemas.xmlsoap.org/ws/2004/03/addressing">
http://name.org/#challenge.solution1.AlignWarpImpl@1bf6770
</Address>
id: http://key.org/1157626153750/13
Query 6
Find all output averaged images of softmean (average) procedures, where the warped images taken as input were align_warped using a twelfth order nonlinear 1365 parameter model, i.e. "where softmean was preceded in the workflow, directly or indirectly, by an align_warp procedure with argument -m 12." Answering this query is a three step process:- Find interactions involving the softmean actor
- Find the provenance of the outputs of those interactions, i.e. the process that led to those the averaged images
- Find within the provenance, an invocation that takes "-m 12" as an argument
(1) $ps:pstruct/ps:interactionRecord/ps:sender (2) [ps:actorStatePAssertion/ps:content/ap:ActorProfile/ap:name='Softmean'] (3) /../ps:interactionKeyThe second step is a provenance query with a very similar form to that used in Query 1. In the provenance query below, the source and sink URLs shown in lines (2) and (3) are gathered from the above XQuery, i.e. they relate to the interactions of the softmean actor.
(1) builder.getQDHBuilder ().
(2) sourceURL (source).
(3) sinkURL (sink).
(4) sender ().
(5) contentItem ("/java/object/void/array");
The third step involves iterating over the results of the provenance query, as shown in the Java code below. For each interaction, we perform an XQuery, shown below the code, which detects whether there is an argument "-m 12 q". If so (if the query returns any results), then we have found the output (the interaction from the first step) we are looking for, and so output the result.
while (eachRel.hasNext ()) {
ikey = ((FullRelationship) eachRel.next ()).getSubject ().getGlobalPAssertionKey ().getInteractionKey ();
source = ikey.getMessageSource ().getTextContent ();
sink = ikey.getMessageSink ().getTextContent ();
query = "$ps:pstruct/ps:interactionRecord[ps:interactionKey/ps:messageSource='" + source +
"'][ps:interactionKey/ps:messageSource='" + sink + "'][ps:receiver/ps:interactionPAssertion" +
"/ps:content/java/object/void/array/void/string='-m 12 -q']/ps:interactionKey";
answer = _store.xquery (query);
if (answer.getChildNodes ().getLength () > 0) {
write.write (interaction);
break;
}
}
$ps:pstruct/ps:interactionRecord [ps:interactionKey/ps:messageSource='...source...'][ps:interactionKey/ps:messageSource='...sink...'] [ps:receiver/ps:interactionPAssertion/ps:content/java/object/void/array/void/string='-m 12 -q'] /ps:interactionKeyThe results of the query are given here.
Query 7
A user has run the workflow twice, in the second instance replacing each procedures (convert) in the final stage with two procedures: pgmtoppm, then pnmtojpeg. Find the differences between the two workflow runs. The exact level of detail in the difference that is detected by a system is up to each participant. First, we find all occurrences of Atlas X Graphic being outputted in the provenance store, using the XQuery shown below.$ps:pstruct/ps:interactionRecord [ps:receiver/ps:interactionPAssertion/ps:content /java/object/void/object/string='challenge/atlas-x.gif'] /ps:interactionKeyFor each output, we then perform exactly the same provenance query as shown in Query 1. Each provenance query result describes a single run of the workflow, i.e. the process that led to the particular Atlas X Graphic. We then iterate over the results and extract the actor types in every interaction included in the provenance query results. An actor type is given in an actor state p-assertion, and extracted with the XQuery shown below the Java code.
for (int count = 0; count <= 1; count += 1) {
actors [count] = new HashSet ();
eachIK = ProvenanceQueryUtilities.extractInteractionKeys (process1).iterator ();
while (eachIK.hasNext ()) {
interaction = (InteractionKey) eachIK.next ();
actors [count].add (getActorType (interaction, true));
actors [count].add (getActorType (interaction, false));
}
}
getActorType
$ps:pstruct/ps:interactionRecord[ps:interactionKey/ps:messageSource/wsa:Address='...source...'] [ps:interactionKey/ps:messageSink/wsa:Address='...sink...'] [ps:interactionKey/ps:interactionId='...interactionId...'] /ps:sender /ps:actorStatePAssertion/ps:content/ap:ActorProfile/ap:typeFinally, the sets of actor types for the different workflow runs are compared. In the second run, we find three new actor types: pgmtogif, jpegtogif and pgmtojepg. Therefore, the difference between the workflow runs are the presence of these actors. The results of the query are as follows:
Difference in actors [http://type.org/JpegtoGif, http://type.org/PgmtoGif, http://type.org/PgmtoJpeg]An alternative approach to using provenance queries to identify processes, is to use tracers. As described earlier, a tracer conveniently demarcates a process by being included in all and only the messages sent in that process. Therefore, searching for p-assertions containing the tracer finds the documentation of the whole process.
Query 8
A user has annotated some anatomy images with a key-value pair center=UChicago. Find the outputs of align_warp where the inputs are annotated with center=UChicago. Annotations in the challenge are included in the process documentation as actor state p-assertions. They therefore have a particular meaning: they are annotations regarding the contents of an interaction or actor state and are true at a particular instant. These annotations cannot be modified. For these reasons, they are different from general annotations found in metadata stores. To answer this query, we need a six step process.- Download the annotations from the store
- Find to which interaction the annotation center=UChicago is attached
- Get the argument, i.e. the anatomy image file, in this interaction
- Find the align_warp actor that inputs that anatomy image file
- Find the interaction in which that align_warp actor outputs the warp parameters for that image file
- Get the result, i.e. the warp parameter file, from that interaction
$ps:pstruct/ps:interactionRecord/*/ps:actorStatePAssertion /ps:content/ann:AnnotationThe next XQuery takes the interaction key from the previous step and finds the data file sent as input in that interaction, i.e. the annotated image.
$ps:pstruct/ps:interactionRecord[ps:interactionKey/ps:messageSource/wsa:Address='...source...'] [ps:interactionKey/ps:messageSink/wsa:Address='...sink...'] [ps:interactionKey/ps:interactionId='...iid...'] /ps:sender/ps:interactionPAssertion/ps:content/java/object/void/array/void/object/stringThe next XQuery finds an invocation in which an actor of type align_warp which takes that data as input.
$ps:pstruct/ps:interactionRecord/ps:receiver [ps:actorStatePAssertion/ps:content/ap:ActorProfile/ap:type='http://type.org/AlignWarp'] [ps:interactionPAssertion/ps:content/java/object/void/array/void/object/string='...data...'] /../ps:interactionKeyThe next XQuery finds the relationship p-assertion which relates the output of the align_warp actor to its input, where the input is the invocation found in the preceding step.
$ps:pstruct/ps:interactionRecord /*/ps:relationshipPAssertion[ps:relation='...relation...'] /ps:objectId [ps:interactionKey/ps:messageSource/wsa:Address='...source...'] [ps:interactionKey/ps:messageSink/wsa:Address='...sink...'] [ps:interactionKey/ps:interactionId='...iid...'] [ps:dataAccessor/xPath="/java/object/void[@property='args']/array/void[index='0']"] /../../../ps:interactionKeyFinally, for the output of align_warp above, we find the data item that is output, i.e. the warp parameters file. This query is the one performed below.
$ps:pstruct/ps:interactionRecord[ps:interactionKey/ps:messageSource/wsa:Address='" + source + "'] [ps:interactionKey/ps:messageSink/wsa:Address='" + sink + "'] [ps:interactionKey/ps:interactionId='" + iid + "'] /ps:sender/ps:interactionPAssertion/ps:content/java/object/void/object/stringThe results of the query are as follows:
Result of processing file annotated with center=UChicago: challenge/warp1.warp
Query 9
A user has annotated some atlas graphics with key-value pair where the key is studyModality. Find all the graphical atlas sets that have metadata annotation studyModality with values speech, visual or audio, and return all other annotations to these files. The solution for this query uses the first step of Query 8 to get all annotations. Then, for the data item to which studyModality=speech, visual or audio is attached, the rest of the annotations attached to that data item are returned.Annotations on image annotated with studyModality: [center=southampton, null, studyModality=speech]
Suggested Workflow Variants
Levels of Abstraction
Our approach allows us to determine the provenance of data items at different levels of abstraction. For example, in Query 7, theconvert actor is replaced by two other actors, pgmtoppm and pnmtojpeg. An alternative arrangement is for convert to be a service that itself calls pgmtoppm then pnmtojpeg to achieve its function. We can then see this part of the process at two levels of abstraction:
- Coarse-Grained: The provenance includes only the five steps shown in the provenance challenge workflow, with
convertbeing the fourth step. - Fine-Grained: The provenance includes the calls of
convertto each of thepgmtoppmandpnmtojpegactors.
convert actor.
The following collaboration diagram shows the workflow at the finer granularity.
Security
Our provenance stores may be configured to require p-assertions to be signed before they are recorded. The signatures can then be checked against the asserter's identity in the p-structure.Suggested Queries
Our approach would enable us to answer other queries not suggested in the first challenge. These particularly relate to security and distribution.Signatures
An organisation providing aslicer service, states that this was used in the workflow instead of the one claimed by the scientist. Determine which service provider was actually used.
Because each p-assertion is made by the actor (service) that is involved in the event the p-assertion documents, and because our data structure allows signatures on recorded p-assertions to be made available to queriers, we can check that the signature matches that of the owning organisation for a service.
Distributed Stores and Technology Independence
The averaged image was generated, i.e. the first three stages of the workflow were run, by members of one organisation. They used workflow enactment technology X. Then, independently, the averaged image was sliced and converted into GIFs by another scientist using workflow enactment technology Y. Determine the provenance of one of the final images. Because our data model is independent of the technology on which processes are performed, and links can be recorded between p-assertions in different provenance stores, it is possible to find the provenance of the final images in exactly the same way as presented in Query 1 even when different workflow technologies and multiple provenance stores are used.Multiple Views
From the p-assertions recorded by the align_warp service, we determine that it output particular warp parameters. However, the final results do not appear to correspond with those parameters. Check that the reslice service received these warp parameters. Because all actors in our model receord their view of any interaction, we have interaction p-assertions containing the data as sent and as received in any interaction. This allows us to pick up errors.Categorisation of queries
We could (loosely) categorise the challenge queries in the following way:- Those related to provenance, i.e. how a data item came to be as it is, which is the focus of queries 1, 2, 3
- Those related to properties of process, i.e. queries based on the structure of the process that occurred, which is the focus of queries 4, 5, 6 and 7
- Those related to annotations of data, i.e. not the process itself but metadata attached to its products, which is the focus of queries 8 and 9
Live systems
No live system is currently available, but all our software tools can be downloaded and used from provenance.ecs.soton.ac.uk.Further Comments
No further comments.Conclusions
The approach we have taken is adequate for answering the queries presented by the provenance challenge. In particular, questions regarding the provenance of data, how the data came to be as it is, in itself are straightforward to answer using provenance queries. The data structure given to documentation of processes, the p-structure, allows questions to be answered about that processes and, while it is not the focus or strength of the work, annotations of data and questions regarding them are possible due to the openness of the data model. Features of our data model include:- Relationships: assertions of causal relations between data items and events in a process, allowing the provenance of data to be straightforwardly determined.
- Views: each actor can assert its own p-assertions about an event.
- Documentation style: data can be expressed in many ways included encrypted, translated to a more searchable form, by reference etc.
- Tracers: processes can be demarcated by tracers automatically exchanged between actors in the process.
- Signatures: p-assertions can be signed and these signatures made available for others to verify.
to top
| I | Attachment  | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| | p-assertions.jpg | manage | 116.7 K | 06 Sep 2006 - 06:05 | LucMoreau | |
| | p-assertions.gif | manage | 12.1 K | 06 Sep 2006 - 06:18 | LucMoreau | |
| | p-assertions-468-318.gif | manage | 14.9 K | 06 Sep 2006 - 06:27 | LucMoreau | |
| | collaboration.gif | manage | 35.5 K | 06 Sep 2006 - 06:39 | LucMoreau | |
| | matrix2.gif | manage | 10.4 K | 06 Sep 2006 - 13:16 | LucMoreau | |
| | matrix3.gif | manage | 22.7 K | 06 Sep 2006 - 13:21 | LucMoreau | |
| | AlignWarImplSelected.gif | manage | 5.8 K | 06 Sep 2006 - 14:56 | LucMoreau | |
| | matrix.pdf | manage | 30.4 K | 06 Sep 2006 - 14:56 | LucMoreau | |
| | matrix.gif | manage | 26.2 K | 06 Sep 2006 - 14:57 | LucMoreau | |
| | resliceImplSelected.jpg | manage | 39.5 K | 06 Sep 2006 - 15:02 | LucMoreau | |
| | resliceImplSelected.gif | manage | 7.3 K | 06 Sep 2006 - 15:05 | LucMoreau | |
| | SoftmeanImplSelected.gif | manage | 7.0 K | 06 Sep 2006 - 16:31 | LucMoreau | |
| | SlicerImplSelected.gif | manage | 8.7 K | 06 Sep 2006 - 16:33 | LucMoreau | |
| | challenge.gif | manage | 162.9 K | 06 Sep 2006 - 16:38 | LucMoreau | |
| | bigbang-cropped.gif | manage | 53.2 K | 06 Sep 2006 - 16:47 | LucMoreau | |
| | pstruct-small.jpg | manage | 118.1 K | 06 Sep 2006 - 17:07 | LucMoreau | |
| | ir.jpg | manage | 33.9 K | 06 Sep 2006 - 17:07 | LucMoreau | |
| | sender.jpg | manage | 45.5 K | 06 Sep 2006 - 17:08 | LucMoreau | |
| | ik.jpg | manage | 93.6 K | 06 Sep 2006 - 17:08 | LucMoreau | |
| | collaboration-variant-cropped.gif | manage | 48.0 K | 06 Sep 2006 - 18:06 | LucMoreau | |
| | interactionKey.jpg | manage | 55.9 K | 10 Sep 2006 - 20:52 | PaulGroth | |
| | interactionRecord.jpg | manage | 20.3 K | 06 Sep 2006 - 21:26 | PaulGroth | |
| | senderView.jpg | manage | 24.1 K | 06 Sep 2006 - 21:27 | PaulGroth | |
| | pstruct.jpg | manage | 27.3 K | 07 Sep 2006 - 10:22 | PaulGroth | |
| | question1.xml | manage | 303.7 K | 08 Sep 2006 - 11:02 | SimonMiles | Query 1 Results |
| | question2.xml | manage | 25.4 K | 08 Sep 2006 - 11:02 | SimonMiles | Query 2 Results |
| | question3.xml | manage | 79.2 K | 08 Sep 2006 - 11:03 | SimonMiles | Query 3 Results |
| | question4.xml | manage | 3.3 K | 08 Sep 2006 - 11:03 | SimonMiles | Query 4 Results |
| | question5.txt | manage | 0.5 K | 08 Sep 2006 - 15:15 | SimonMiles | Query 5 Results |
| | question6.xml | manage | 0.6 K | 08 Sep 2006 - 11:04 | SimonMiles | Query 6 Results |
| | question8.txt | manage | 0.1 K | 08 Sep 2006 - 11:05 | SimonMiles | Query 8 Results |
| | question7.txt | manage | 0.1 K | 08 Sep 2006 - 16:13 | SimonMiles | Query 7 Results |
| | question9.txt | manage | 0.1 K | 08 Sep 2006 - 11:05 | SimonMiles | Query 9 Results |
| | question1.jpg | manage | 86.1 K | 08 Sep 2006 - 16:21 | SimonMiles | Question 1 web image |
| | question1.pdf | manage | 34.5 K | 08 Sep 2006 - 16:21 | SimonMiles | Question 1 hi-res image |
| | question2.jpg | manage | 11.5 K | 08 Sep 2006 - 16:21 | SimonMiles | Question 2 web image |
| | question2.pdf | manage | 2.5 K | 08 Sep 2006 - 16:22 | SimonMiles | Question 2 hi-res image |
| | question3.jpg | manage | 22.6 K | 08 Sep 2006 - 16:23 | SimonMiles | Question 3 web image |
| | question3.pdf | manage | 5.2 K | 08 Sep 2006 - 16:23 | SimonMiles | Question 3 hi-res image |
| | standardsrefstwiki.bib | manage | 11.0 K | 11 Sep 2006 - 19:40 | PaulGroth |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Challenge.Southampton moved from Soton.ProvenanceChallengeResults on 12 Sep 2006 - 15:20 by SimonMiles - put it back