Provenance Challenge: UvA?/VL-e
Participating Team
Team and Project Details
Workflow Representation
The workflow is implemented using a Grid-based workflow system developed at the the University of Amsterdam, called
WS-VLAM. The provenance is, however, handled with an initial version of PLIER (Provenance Layer Infrastructure for e-Science Resources) which is being developed by the Information Management Group at
PCC UvA. Essentially, PLIER hides the details of handling and managing the provenace from WS-VLAM system when it executes the workflow. The WS-VLAM engine uses PLIER, in its API form, to generate provenance data from the workflow into an
OPM graph.
It is clear that the workflow has to be adapted to the WS-VLAM system for its composition and execution. When performing this adaptation, we faced already multiple ways to adjust the command line workflow to its WS-VLAM counter part. It is possible, for instance, to execute some processes by farming them or employ sequential processes instead; or to create a 'big' workflow or use composite workflows (hierarchical). Some of these initial alternatives are described in the slides contained in this
powerpoint file.
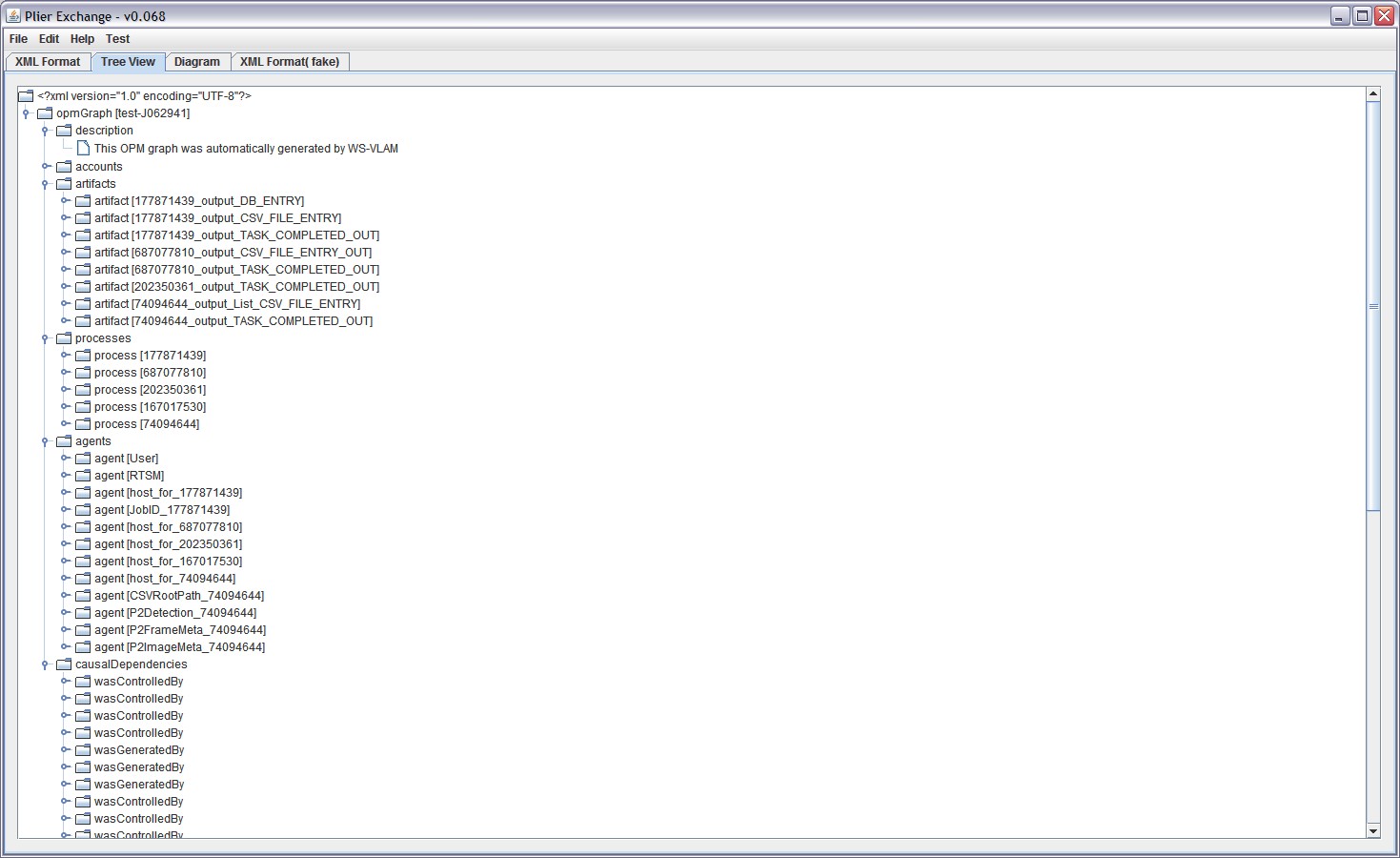
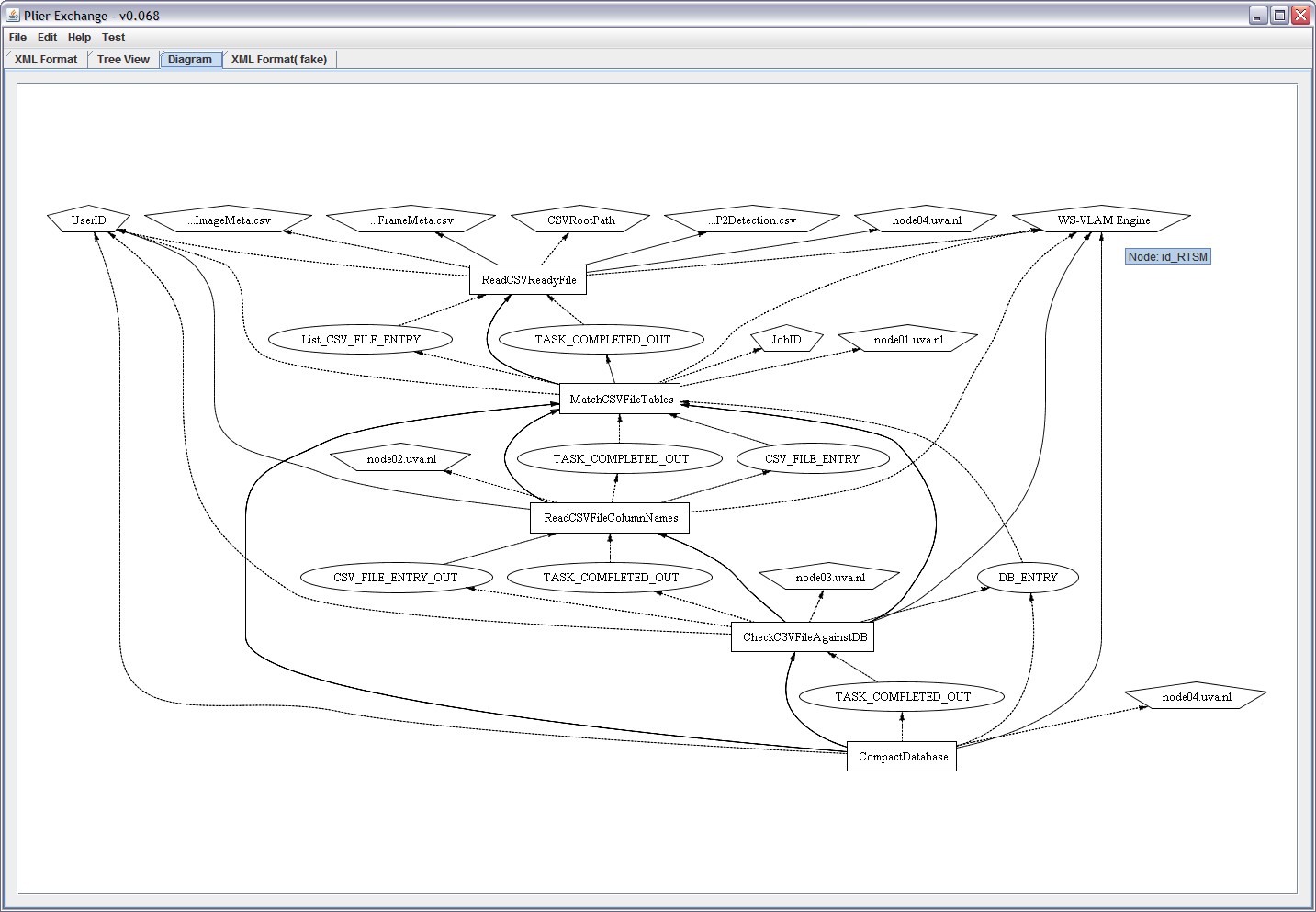
The following figures present the different stages to generate the provenace. On one hand, the Figure 1 shows the WS-VLAM Composer with the design, or representation, of the workflow. On the other hand, the
OPM Graph generated by PLIER can be seen as a XML format, in Figuere 2, or as a diagram, in Figure 3.
 |
 |
 |
| Figure 1. WS-VLAM Composer |
Figure 2. PLIER (XML Tree) |
Figure 3. PLIER (Diagram) |
Similarly to the previous figures, the below representations show the WS-VLAM Composer, in Figure 4, and the PLIER tool, in Figure 5, with a more detailed workflow.
 |
 |
| Figure 4. WS-VLAM Composer (detailed workflow) |
Figure 5. PLIER (detailed workflow) |
Open Provenance Model Output
The following table show the latest
OPM Graphs generated by PLIER from WS-VLAM workflows.
Query Results
The PLIER repository is a relational database that is accessed by scientists indirectly through the GUI tool or programatically via the API. Basically, the PLIER repository handles the data but relies on the GUI end-user application to retrieve or query the information elements. These tools, however, are still under development and they may not be able to
query rather
browse the data. Although PLIER does not provide any low level manipulation mechanisms, it does not restrict the user from accessing through SQL commands. Thus, for the sake of providing some clarification, the
OPM data will be then queried using both OQL and SQL.
Query 1
For a given detection, which CSV files contributed to it?
Our solution first notices that the WS-VLAM system is agnostic of what the processes do. The WS-VLAM engine schedules and submits each process for execution, while monitor its progress. The module instead executes its specific task, as a black box, without being aware about the existance of WS-VLAM system. Second, PLIER is meant to provide provenance to the workflow as a whole and, at this moment, it does not consider the granulaity contained by the modules. Under these circumtances, if the
given detection is treated by the any module it, the generated provenace data by itself is insufficient to answer the query.
We can interpret this query from another point of view. In our data provenance, the filenames are provided as parameters to the modules to generate the output (or the input). The parameters are expressed in the
OPM Graph as Agents, having an
ID linking it to the detection and a data
Value. Thus, in order to retrieve the CSV files that contributed to a detection, we perform the following query:
SQL: select Agent.Value from AGENT where Agent.ID like '%Detection%'
Which returns:
P2_J062945_B001_P2fits0_20081115_P2Detection.csv
Another possibility is to employ with a more general query that retrieves the CSV files participating in all events.
SQL: select * from AGENT where Agent.value like '%.csv'
Which returns:
P2_J062945_B001_P2fits0_20081115_P2Detection.csv
P2_J062945_B001_P2fits0_20081115_P2FrameMeta.csv
P2_J062945_B001_P2fits0_20081115_P2ImageMeta.csv
Comment:
- In this second view, we do not see any link between the database internal operations and the generated OPM graph. In the implementation the database is receiving a bulk file that imported into its internal tables. After performing this task, the only information from the database is the number of records either inserted, updated, or deleted. We are answering the query based on the id having 'Detection' or the values having '.csv' (part of the input file name). Clearly, it is not always the case that a file name or its extension reflect its content.
Query 2
The user considers a table to contain values they do not expect. Was the range check ('IsMatchTableColumnRanges') performed for this table?
Query 3
Which operation executions were strictly necessary for the Image table to contain a particular (non-computed) value?
Suggested Workflow Variants
Suggestions for Modification of the Open Provenance Model
OPM Specification
While implementing the necessary mechanisms to import and export information using the
OPM model, based on the given XML Schema (
http://openprovenance.org), we faced some inconveniences while parsing the XML tags. Therefore, we modified the schema to cope with those problems as well to match the database model from the repository. These changes to the original XML schema are summarized below:
- The modified schema basically contains the the same definitions but instead of using complexType constructs, we employ element definitions.
- The main problem for our parser was to unambiguously identify the concept
account since the definition for AccountId and Account share the same element (account) and attribute (id).
- The modified schema takes a generic approach for ids rather than explicitly define
ProcessId, AgentId, or AgentId.
In order to better clarify our points, we attached the
revised XML schema OPMv101.revised.xsd
Conclusions
--
VictorGuevara - 02 Jun 2009
to top

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}